
کمک به تیم های فناوری اطلاعات در مدیریت بهتر حوادث امنیتی
حملات سایبری هر روز به مشاغل ضربه می زنند. در سال های اخیر، با بهره مندی هکرها از سیستم های آسیب پذیر فناوری اطلاعات، این حملات ده برابر افزایش یافته است. مدیریت این تهدیدات امنیتی می تواند باعث شود که احساس کنید در یک حلقه بی پایان گیر کرده اید – یک مشکل را حل می کنید، مشکل دیگری ظاهر می شود.
در ManageEngine، ما در طول سالها با تهدیدات زیادی روبرو بودهایم و رویکرد خود را به امنیت فناوری اطلاعات بهخوبی تنظیم کردهایم. ما به جای اینکه دائماً در حالت اطفاء حریق (دفع خطرات عاجل به وجود آمده) کار کنیم، روی بهبود روش ها و امنیت کلی اطلاعات خود تمرکز می کنیم. این به ما کمک کرد از اشتباهات خود درس بگیریم و چارچوب امنیتی فناوری اطلاعات خود را بهبود ببخشیم.
با توجه به اینکه هکرها به طور پیوسته از روش های مختلف برای نفوذ به سیستم IT شما استفاده می کنند، سه شیوه و تکنیک نحوه دفاع مستمر از سیستم های کامپیوتری را بیان می کنیم.
ایجاد کنترل های جامع
ما مسئولیت رویدادهای امنیتی فناوری اطلاعات را از مرکز عملیات امنیتی خود (SOC) بر عهده می گیریم. برخی از این رویدادها به حوادث امنیتی تبدیل می شوند. در اینجا نحوه برخورد ما با آنها آمده است:
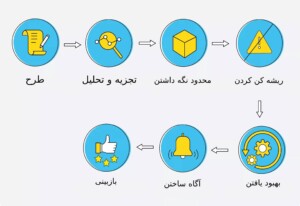
مدیریت حوادث IT
در مرحله تهیه پیشنویس، کنترلهایی را ایجاد میکنیم تا مسئولیت حادثه را بر عهده بگیریم و اطمینان حاصل کنیم که در بهترین موقعیت برای رسیدگی به آن هستیم. تیم SOC اطلاعات (مانند رویدادها و گزارشها) را از چندین منبع جمعآوری میکند. ما کنترل هایی برای کمک به استفاده از این اطلاعات داریم و آنها به ما کمک می کنند تا مسائل مربوط به امنیت را از پایگاه داده اطلاعات خود شناسایی کنیم. رویکرد ما به یک حادثه به این مسائل بستگی دارد.
از یک مثال دسترسی به فایروال استفاده می کنیم. تیم SOC لاگ های فایروال را به طور منظم ذخیره و نظارت می کند. هنگامی که آنها از تلاش های ناموفق برای ورود به کنسول فایروال مطلع می شوند، تیم مدیریت حادثهIM) ) را مطلع می کنند. تیم IM این حادثه را ثبت می کند و یک ارزیابی اولیه را با تیم SOC انجام می دهد. سپس، تیم IM موضوع را با تیم مرکز عملیات شبکه ما (NOC) در میان می گذارد. تیم NOC این مشکل را حل می کند.
به همین ترتیب، تیم SOC آدرسهای IP خارجی را برای آسیبپذیریها بر اساس زمانبندی ثابت اسکن میکند. هنگامی که تیم SOC انحرافات را تشخیص می دهد، با سایر تیم های چارچوب کار می کنند تا آنها را برطرف کنند.
به طور خلاصه، تیم SOC ما کنترلهای امنیتی زیر را اجرا میکند:
کنترل از لاگ های سیستم syslogs
گزارشهای احراز هویت و تاریخچه دستورات به ما کمک میکنند بفهمیم چه کسی به سرورهای ما دسترسی داشته و دستورات مشکلساز را اجرا کرده است.
کنترل از لاگ های فایروال
دسترسی های تایید نشده، تغییرات قوانین و غیره نظارت می شوند و هشدارها را راه اندازی می کنند.
کنترل یکپارچگی فایل
یکپارچگی فایل ها در تمام سرورهای تولیدی نظارت می شود و هشدارها را راه اندازی می کند.
کنترل برای برنامه ها
این کنترل ها مختص به تیم های مجزای اپلیکسشن هستند. تیم SOC یک ارزیابی اولیه را انجام می دهد و با تیم های اپلیکیشن کار می کند تا مشکلات را حل کند.
این کنترل ها مرحله تجزیه و تحلیل ما را به طور قابل توجهی بهبود می بخشد. زمانی که کنترل های امنیتی ما جامع باشد، این مرحله ساده تر و قابل اعتمادتر است.
یک طرح اولیه برای تجزیه و تحلیل حوادث ایجاد کنید
به عنوان مثالی برای درک مرحله بعد، بیایید به نمونه ای از حمله به یکی از سرویس های ما نگاه کنیم. یک کاربر خاص (در این مورد، مهاجم) چندین نمونه از حساب خود را از چندین آدرس IP ایجاد کرد. این رویداد چندین شناسه منحصر به فرد را در پایگاه داده ما برای مهاجم ثبت کرد. با گذشت روزهای بعدی، موارد از 1000 به 2000 دو برابر شد و به رشد تصاعدی ادامه داد.
در یک جایی این تعداد به 14000 مورد در روز رسید. مشکل این جا بود که هر نمونه دارای یک کلید 10 رقمی مرتبط با آن است. با این سرعت، کلیدهای 10 رقمی ما به زودی تمام می شد. علاوه بر این، هر نمونه 30-50 کاربر ثانویه را دعوت کرد و هر کاربر ایمیل دریافت کرد. به طور کلی، ما هر ساعت نزدیک به 5000 تا 25000 ایمیل داشتیم. این موضوع تبدیل به یک حمله گسترده به خدمات ما شد و ما مجبور شدیم رهگیری کنیم.
در اینجا نحوه تجزیه و تحلیل این موضوع با استفاده از طرحی مرحله به مرحله آمده است:
مرحله 1 (بر اساس شواهد)
تعداد اولین مدرک ما بود. همچنین ما متوجه شدیم که مهاجم هر نمونه را با استفاده از پارامترهای معتبر ایجاد کرده است. هر کاربر ثانویه درگیر نیز محتوای توهین آمیز را از آدرس های ایمیل معتبر دریافت کرد. ما این شواهد را از طریق شکایانی که کاربران به تیم سوء استفاده و هرزنامه ما ارسال کرده بودند جمع آوری کردیم.
با استفاده از این شواهد، متوجه شدیم که مهاجم میخواهد تعداد را با استفاده از پارامترهای معتبر افزایش دهد. برای مبارزه با این مسأله، محدودیتی در تعداد موارد در روز تعیین کردیم. از آنجایی که مهاجم از آدرسهای ایمیل معتبر نیز استفاده کرده بود، ما با ارائهدهنده خدمات ایمیل مربوطه تماس گرفتیم تا این حسابهای ایمیل را شناسایی کنیم.
مرحله 2 (بر اساس انگیزه)
از آنجایی که مهاجم از دامنه های ما برای ارسال محتوای هرزنامه استفاده می کرد، برخی از ایمیل های واقعی ما در هرزنامه قرار گرفتند. ما فهمیدیم که این می تواند یکی از انگیزه های آنها باشد. و پس از بررسی بیشتر متوجه شدیم که مهاجم راه حلی برای ایجاد چندین آدرس ایمیل با استفاده از یک الگو پیدا کرده است. آن الگو را دیدیم و حسابهای حاوی آن الگو را مسدود کردیم.
مرحله 3 (بر اساس زیرساخت)
مهاجم از آدرس های IP مختلف استفاده می کرد، بنابراین ما آنها را مسدود کردیم و لیست را از نزدیک زیر نظر گرفتیم. مهاجم همچنین از آدرس های ایمیل معتبر برای کاربران ثانویه استفاده میکرد. هنگامی که الگوی مورد استفاده مهاجم برای دستیابی به این هدف را شناسایی کردیم، کنترل های فایروال را ایجاد کردیم و برنامه هایی را برای محدود کردن تعداد نمونه ها ایجاد کردیم. ما چک های بیشتری را در مرحله ایجاد معرفی کردیم و تعداد ایمیل ها را محدود کردیم.
این تحلیل مرحله ای به ما کمک کرد تا آسیبی را که مهاجم سعی داشت وارد کند، مهار کنیم. همچنین به ما کمک کرد تا اقداماتی را برای پاسخ دادن به مهاجم انجام دهیم، در حالی که بر سایر کاربران واقعی تأثیر نگذارد. ما این حادثه را حل کردیم، آسیبها را مهار کردیم و کنترلهایی را قرار دادیم تا دیگر حمله هرزنامه مشابهی رخ ندهد. ما همچنین این دانش را با سایر تیم های کاربردی به اشتراک گذاشتیم.
در منیج انجین نقشه های مشابهی برای مدیریت حملات DDoS، brute-force و سایر حملات داریم. اگر برای سازمان شما مناسب است، می توانید چنین طرح هایی را نیز ایجاد کنید.
از فرمولی برای مهار تأثیر یک حادثه استفاده کنید
مواردی وجود داشته است که به دلیل یک حادثه امنیتی مجبور شده ایم فوراً به کنترل آسیب بپردازیم. بیایید سناریویی را در نظر بگیریم که یکی از تیم های محصول ما قطعه ای از کد نادرست را اجرا می کرد. تیم محصول مربوطه به تازگی یک رویداد تبلیغاتی (ایونت) را به پایان رسانده بود. با این حال، یک سری ایمیل در مورد این رویداد به طور خودکار برای مجموعه ای از کاربران ارسال شد.
به محض اینکه مدیریت حادثه ما از این اتفاق مطلع شد، با تیم های محصول کار کردند تا تأثیرات را مهار کنند. ما متوجه شدیم که کد معیوب باعث ایجاد ایمیلها میشود. بلافاصله یک راه حل موقت برای متوقف کردن ایمیل ها ایجاد و همچنین علت اصلی را پیدا کردیم و راهحلهای دائمی را اجرا کردیم.
خوشبختانه، ما زود متوجه آن شدیم، بنابراین ایمیلها فقط برای کارمندانی ارسال شده بود که با حسابهای آزمایشی ثبتنام کرده بودند. اگر وضعیت را کنترل نمیکردیم، میتوانست به نقض حریم خصوصی و از دست دادن اعتماد منجر شود.
فرمول یا سیستمی داریم که در چنین حوادثی به ما کمک می کند. برخی از نکات برجسته آن سیستم عبارتند از:
یک اصلاح موقت ایجاد کنید
ما مهندسین را در زمینه ایجاد یک راه حل سریع موقت آموزش می دهیم. ما با چک لیست ها به آنها کمک می کنیم تا مطمئن شویم که راه حل به درستی کار می کند. هنگامی که اعضای تیم آنها یک اصلاح موقت را انجام می دهند، به مدیران هشدار داده می شود.
بیلد (ساختار) مشکل ساز را برگردانید
بیلد بخشی از کد است که توسعه دهندگان آن را به سرورهای مولد وارد میکنند. اگر مشکلی دارد، بازگرداندن آن باید دانشی عمومی باشد یعنی همه اعضای تیم توانایی علم آن را داشته باشند. تیم های ارائه خدمات ما با توسعه دهندگان همکاری می کنند تا به آنها کمک کنند تا ساخت های مشکل ساز را بازگردانند و آنها را عیب یابی کنند.
سیستمهای وصلهای (Patch) با بیلدهای Hotfix
توسعه دهندگان ما از به روزرسانیهای Hotfix برای رفع فوری مشکل در صورت نیاز استفاده میکنند. ما منابع کافی برای کمک به توسعه دهندگان ارائه می دهیم تا با امنیت خاطر کار کنند.
غیر فعال کردن ویژگی ها
گاهی اوقات، ممکن است نتوانیم کد دقیق اشتباه را تشخیص دهیم یا به سرعت کافی به یک تعمیر موقت برسیم. در این مورد، ما ویژگیهای خاصی را غیرفعال میکنیم تا تاثیر منفی را متوقف کنیم و برای خود زمان بخریم تا راه حلهایی را ابداع کنیم. ما همچنین اطمینان می دهیم که کاربران از وضعیت آگاه هستند.
سیستم ها را از شبکه جدا کنید
هنگامی که ما نیاز داریم فوراً تأثیر را متوقف کنیم، سیستم های مشکل ساز را از شبکه خود حذف می کنیم. ما همچنین به کاربران آسیبدیده اطلاع میدهیم و تا زمانی که حادثه را مهار کنیم و خدمات را بازیابی کنیم، با آنها کار میکنیم.
نکاتی را در مورد نقاط پایانی مشکل دار درج کنید
در پایگاه داده ما از جنبههای امنیتی مربوط به سیستمهایمان، ما اصرار داریم که توسعه دهندگان جزئیات فنی در مورد نقاط پایانی مشکل ساز را در هنگام جستجوی مشکلات برای سرعت بخشیدن به عیبیابی بگنجانند.
رویدادهای امنیتی حتماً شما را به چالش خواهند کشید. با این حال، آنها می توانند شما را برای بهتر شدن متحول کنند. مواجهه با این چالش ها کمک میکند تا این تکنیک ها را بسازیم. اگر می خواهید چنین تکنیک هایی را طراحی و اجرا کنید، می توانید با ایجاد یک تیم امنیت، اطلاعاتی را که یاد گرفته اید اجرا نمایید. برای کسب اطلاعات بیشتر در مورد نحوه مواجهه ما با حوادث امنیت سایبری و به طور کلی سایر حوادث، کتاب راهنمای IM ما را بررسی کنید.
ارسال یک دیدگاه