

تجزیه و تحلیل پیش بینی کننده
3 روشی که ManageEngine از قدرت تجزیه و تحلیل پیش بینی کننده در فناوری اطلاعات استفاده می کند
تصور کنید که شما یک جلسه با هیئت مدیره در ساعت 9:30 صبح و بعد از آن یک کنفرانس تلفنی با مشتریان بین المللی دارید. می دانید که جلسات هیئت مدیره دیر برگزار می شود زیرا قبلاً در تعداد زیادی از این گونه جلسه ها شرکت کرده اید. بر این اساس، تماس را برای ظهر برنامه ریزی می کنید و در بین جلسه هیئت مدیره و کنفرانس تلفنی با مشتریان بین المللی زمانی اضافه برای خودتان در نظر میگیرید. شما فقط یک نتیجه را بر اساس داده های گذشته پیش بینی کرده اید. این همان کاری است که تحلیل پیشبینیکننده در مقیاس بزرگتر انجام میدهد.
عملیات سنتی IT از یک رویکرد واکنشی و رفع مشکلات-همانطور که رخ می دهد- پیروی می کند. تجزیه و تحلیل پیش بینی کننده به مثابه عامل تغییر دهنده رویکرد نزد مدیران IT است. این شاخهای از هوش مصنوعی است که از دادههای تاریخی، آمار و الگوریتمها برای پیشبینی نتایج آینده استفاده میکند و این پیشبینیها را به بینشهای عملی برای مدیریت فعالانه عملیات تبدیل میکند.
چارچوب تحلیل پیش بینی
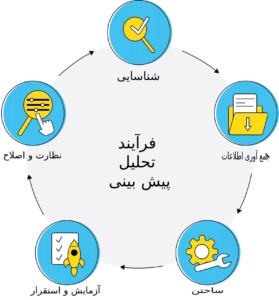
چهار چوب فرآیند تحلیل پیش بینی کننده به طور خلاصه
شناسایی کنید
محدوده مدل خود را مشخص کنید. سعی می کنی چه مشکلی را حل کنی؟ مخاطب شما کیست؟
به عنوان مثال، تعدادی از تکنسین های ما نتوانستند SLA خود را برای این سه ماهه برآورده کنند، و ما می خواستیم دلیل آن را بفهمیم. با پاسخ به این سؤالات، دامنه این موضوع را مشخص می کنیم:
چی شد؟
تکنسین ها نتوانستند تمام تیکت های ارجاع شده به آنها را حل کنند.
چرا این اتفاق افتاد؟
به برخی از تکنسین ها تیکتهای بیشتری نسبت به سایرین اختصاص داده شد. هر هفته آنها برخلاف بقیه تکنسین ها با مسائل پیچیده تری مواجه می شدند.
بعد از این چه خواهد شد؟
23 درصد از تیکت ها به سه ماهه آینده موکول خواهند شد. در نتیجه کاربران نهایی از تأخیر به وجود آمد ناراضی خواهند بود.
چه کنیم؟
باید دلیل تخصیص نامتناسب و پیچیدگی تیکت ها را مشخص کنیم.
داده ها را جمع آوری کنید
ما داده ها را از منابع مختلف برای تجزیه و تحلیل متشکل از داده های تاریخی و بلادرنگ جمع آوری می کنیم. در این سناریو، ما دادههای گذشته تکنسینها را بازیابی میکنیم، از جمله:
الگوی تخصیص تیکت در گذشته.
SLA تکنسین ها در سه ماهه قبلی.
ماهیت و پیچیدگی تیکت هایی که قبلاً به آنها پاسخ می دادند.
رویکرد فعلی آنها به تیکت های پیچیده.
داده ها در سه دسته اول ساختار یافته هستند: داده های تاریخی در پایگاه داده ما موجود است. از سوی دیگر، دادههای دسته آخر بدون ساختار هستند. ما داده های ساختاریافته و بدون ساختار را برای بهبود تحلیل خود جمع آوری می کنیم.
ساختن
دهها مدل پیشبینی وجود دارد که میتوانید آنها را برای رفع نیازهای خاص هر مشکل فناوری اطلاعات تنظیم کنید. رگرسیون متداول ترین مدل مورد استفاده برای تحلیل و پیش بینی آماری است. رابطه بین دو عامل را تخمین می زند. به عنوان مثال، آیا رابطه ای بین SLA ها و تعداد درخواست های نصب نرم افزار در دو سال گذشته وجود دارد؟ اگر وجود داشته باشد، به نحو مقتضی به آن عمل می کنیم.
از روش های ساده مانند روش خط مستقیم می توان برای پیش بینی استفاده کرد. به عنوان مثال، تعداد تیکت ها در شیفت شب سه ماهه سوم سال 2022 با چه تعداد می تواند باشد؟ یک فرمول ساده با توجه به داده های گذشته، می تواند پاسخ این سوال را به شما بدهد.
تست و استقرار
مدل خود را تست و تایید کنید در ابزار تجزیه و تحلیل پیشرفته خود، صحت پیشبینیها را با استفاده از پنهانسازی تأیید میکنیم. این نوعی از یک تست است که از نتایج پیش بینی برای تخمین نقاط داده گذشته و تأیید آنها با داده های تاریخی واقعی استفاده می کند. پس از تکمیل تأیید، موتور پیش بینی نقاط داده را نمایش می دهد.
مثلاً در مثال قبلی با استفاده از رگرسیون خطی، فرمولی را استخراج کردیم که رابطه بین SLA ها و تعداد درخواست های نصب نرم افزار را ایجاد می کند. ما این فرمول را با گرفتن داده های تاریخی از سال 2017 تأیید می کنیم تا ببینیم آیا آن فرمول به اندازه کافی دقیق است یا خیر.
بیایید به سه سناریو نگاه کنیم که در آن از تجزیه و تحلیل پیش بینی کننده برای تغییر ITops خود استفاده می کنیم.
سناریوی 1: پیش بینی تعداد درخواست های خدمات
این سناریو بسط نمونه قبلی ما است. فرض کنید تعداد درخواست های خدماتی که دریافت می کنیم به دلیل افزایش استخدام افزایش یافته است. تعداد درخواستها برای تیم فناوری اطلاعات ما تنها زمانی افزایش مییابد که دستگاههای بیشتری را به شبکه خود اضافه کنیم و مراکز داده خود را گسترش دهیم. ما باید به تناسب اندازه تیم فناوری اطلاعات خود را گسترش دهیم و در عین حال راه حل های بیشتری را به آنها ارائه دهیم. علاوه بر این، ما همچنین می خواهیم تکنسین های ما درک بهتری از سیستم درخواست خدمات ما داشته باشند و عملکرد خود را بهبود بخشند.
اگر بتوانیم تعداد بلیط هایی را که طی چند فصل آینده دریافت خواهیم کرد، پیش بینی کنیم، می توانیم تیم فناوری اطلاعات خود را بر این اساس توسعه دهیم.
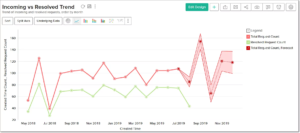
روند پاسخگویی به تیکت ها
هنگامی که با روش های دیگر تجزیه و تحلیل ترکیب می شود، به ما امکان می دهد به سؤالاتی مانند:
معمولا چه زمانی شاهد افزایش تعداد تیکت ها هستیم؟
چرا شاهد این افزایش هستیم؟
در چند ماه آینده چه روندی را می توانیم انتظار داشته باشیم؟
چگونه تعداد آنها را پایین بیاوریم؟
چگونه می توانیم برای اوج (افزایش ناگهانی در تعداد) بعدی آماده شویم؟
پاسخ به این سؤالات به ما کمک می کند تا جهش بعدی را پیش بینی کنیم و برای آن آماده شویم. در این مورد، داده های جمع آوری شده می تواند لیست تکنسین ها، تعداد درخواست ها و تعداد تیکتهای حل شده در هر ماه باشد. پارامترهای دیگری نیز وجود دارد که ما استفاده می کنیم و آنها را با این روند مرتبط می کنیم.
سناریو 2: تشخیص ناهنجاری ها
ناهنجاری زمانی است که جنبه خاصی از تجارت از روندهای مورد انتظار منحرف شود. تشخیص ناهنجاری روشی برای تشخیص یک نقطه غیرعادی از یک مجموعه داده معین است. ما از این تکنیک در موارد زیادی استفاده می کنیم:
ناهنجاری های نقطه ای:
این زمانی است که یک نمونه منحصر به فرد از بقیه فاصله دارد. به عنوان مثال، اگر ترافیک یک آدرس IP خاص در طول یک بعد از ظهر به طور غیرعادی بالا باشد، ابزارهای تجزیه و تحلیل به تیم عملیات شبکه ما هشدار می دهند. تیم این نقطه داده (ترافیک بالا در ساعت 3 بعد از ظهر) را بررسی می کند و تعیین می کند که آیا نیاز به استفاده از قانون فایروال جدید دارد یا کاربر را در مورد ناهنجاری مطلع می کند و به او اجازه می دهد اقدامی انجام دهد.
ناهنجاری های زمینه ای:
این زمانی است که ناهنجاری در یک زمینه خاص خاص است. برای تشخیص این ناهنجاری ها به داده های سری زمانی دقیق (جمع آوری نقاط داده در طول زمان) نیاز داریم.
یک داشبورد متعادل کننده بار را در نظر بگیرید که یک بار غیرعادی را از یک سرور خاص در یک منطقه در طول تعطیلات ملی تشخیص می دهد. افزایش بار در روزهای دیگر قابل قبول است، اما می تواند چیز دیگری را نشان دهد، مانند حمله، در تعطیلات رسمی. تشخیص این ناهنجاری به ما کمک می کند تا برای حمله احتمالی آماده شویم.
ناهنجاری های جمعی:
مجموعه ای از رخدادها به طور جمعی به ما کمک می کنند تا یک ناهنجاری را تعیین کنیم. به عنوان مثال، اگر کارکنانی که روی مجموعهای از محصولات کار میکنند، مکرراً درخواست دسترسی به دادههای تولید را داشته باشند، میتواند نشان دهنده یک حادثه بالقوه باشد. تیم فناوری اطلاعات ما این ناهنجاری را شناسایی کرده و برای جلوگیری از احتمال وقوع یک حادثه بیشتر تجزیه و تحلیل می کند.
همچنین باید از تعداد کل ناهنجاری ها آگاه باشیم. به عنوان مثال، در زیر خلاصه ای از تعداد کل ناهنجاری های شناسایی شده در مرورگرها ذکر می گردد. اگر در طول زمان متوجه افزایش ناهنجاری ها شویم، می تواند نشان دهنده یک مشکل بزرگتر باشد. این تجزیه و تحلیل به ما کمک می کند تا آن را زود تشخیص دهیم و اقدامات لازم را انجام دهیم.
سناریو 3: نظارت بر استفاده از دارایی
همانطور که مشتریان بیشتری اضافه می کنیم، باید ظرفیت خود را برای پردازش داده های آنها به طور متناسب افزایش دهیم. به طور مداوم از ما خواسته می شود که سرورهای بیشتری تهیه کنیم تا تیم های محصول ما بتوانند عملکرد مطلوبی داشته باشند. به عنوان مثال، تیم فناوری اطلاعات ما قصد دارد سرورهای بیشتری را به یک مرکز داده خاص اضافه کند. تیم فناوری اطلاعات باید برای قفس مرکز داده (Data center cage) آماده شود، برای منبع تغذیه راه حل های لازم را تدارک ببیند، فضای فیزیکی کافی ایجاد کند، و غیره.
ارسال یک دیدگاه